
机器学习算法-分类任务
2025/1/15
#机器学习#分类算法#scikit-learn#数据可视化#逻辑回归
机器学习算法-分类任务
scikit-learn: machine learning in Python — scikit-learn 1.7.2 documentation
分类任务-手写数字预测
小插曲,顺手练习一下数据可视化
可以看一下这个数据集,我们尝试可视化一下第一个数据
digits = datasets.load_digits()
X,y = digits.data,digits.target
print(X[0])
####
[ 0. 0. 5. 13. 9. 1. 0. 0. 0. 0. 13. 15. 10. 15. 5. 0. 0. 3.
15. 2. 0. 11. 8. 0. 0. 4. 12. 0. 0. 8. 8. 0. 0. 5. 8. 0.
0. 9. 8. 0. 0. 4. 11. 0. 1. 12. 7. 0. 0. 2. 14. 5. 10. 12.
0. 0. 0. 0. 6. 13. 10. 0. 0. 0.]是一个64个一维数组,用numpy把他变成8*8的
digit_image = np.reshape(X[0], (8,8))
print(digit_image)
print("数据形状"+digit_image.shape)
####
[[ 0. 0. 5. 13. 9. 1. 0. 0.]
[ 0. 0. 13. 15. 10. 15. 5. 0.]
[ 0. 3. 15. 2. 0. 11. 8. 0.]
[ 0. 4. 12. 0. 0. 8. 8. 0.]
[ 0. 5. 8. 0. 0. 9. 8. 0.]
[ 0. 4. 11. 0. 1. 12. 7. 0.]
[ 0. 2. 14. 5. 10. 12. 0. 0.]
[ 0. 0. 6. 13. 10. 0. 0. 0.]]
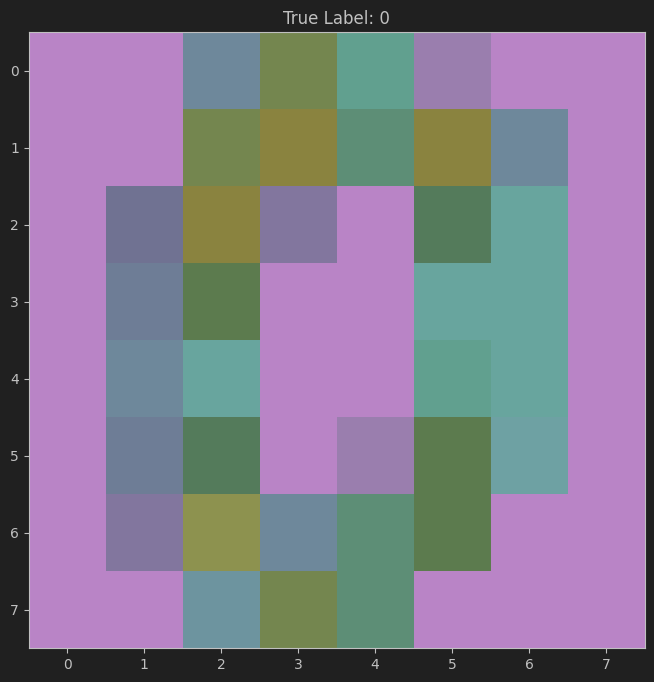
(8, 8)使用plt直接可视化一下,这里cmap搞了一个彩色的,突出一下视觉感
plt.figure(figsize=(8,8))
plt.imshow(digit_image, cmap=plt.cm.viridis, interpolation='nearest')
plt.title(f'True Label: {y[0]}')
plt.show()效果如下,这个数据集主要是把手写的数据,映射成一个一维数组
回到正题,我们这里学习的是
from sklearn import datasets
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
digits = datasets.load_digits()
X,y = digits.data,digits.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
clf = LogisticRegression(max_iter=10000)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print("预测结果", y_pred[:30])
print("真是结果", y_test[:30])
print(accuracy_score(y_test, y_pred))
'''
C:\Users\bx336\PycharmProjects\machine\.venv\Scripts\python.exe C:\Users\bx336\PycharmProjects\machine\start\1.py
预测结果 [6 9 3 7 2 1 5 2 5 2 1 9 4 0 4 2 3 7 8 8 4 3 9 7 5 6 3 5 6 3]
真是结果 [6 9 3 7 2 1 5 2 5 2 1 9 4 0 4 2 3 7 8 8 4 3 9 7 5 6 3 5 6 3]
0.9685185185185186
'''这里一个细节我觉得是数据分割的处理
一个数据集一部分用于训练,一部分用于这个测试
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
其实也比较好理解,看一下具体参数就行
test_size表示测试集占数据总量的 20%,训练集就是剩下的 80%。random_state=42随机数种子
最后一个就是accuracy_score
from sklearn.metrics import accuracy_score
y_true = [0, 1, 2, 2, 0] # 真实标签
y_pred = [0, 0, 2, 2, 0] # 模型预测
acc = accuracy_score(y_true, y_pred)
print(acc)Accuracy=正确的样本数 / 总样本数预测