
前段时间我们团队搞了一个AI4CodeQL的智能漏洞挖掘项目,这里总结几篇关于CodeQL的文章
第一篇就是分析一下数据创建,查询的问题
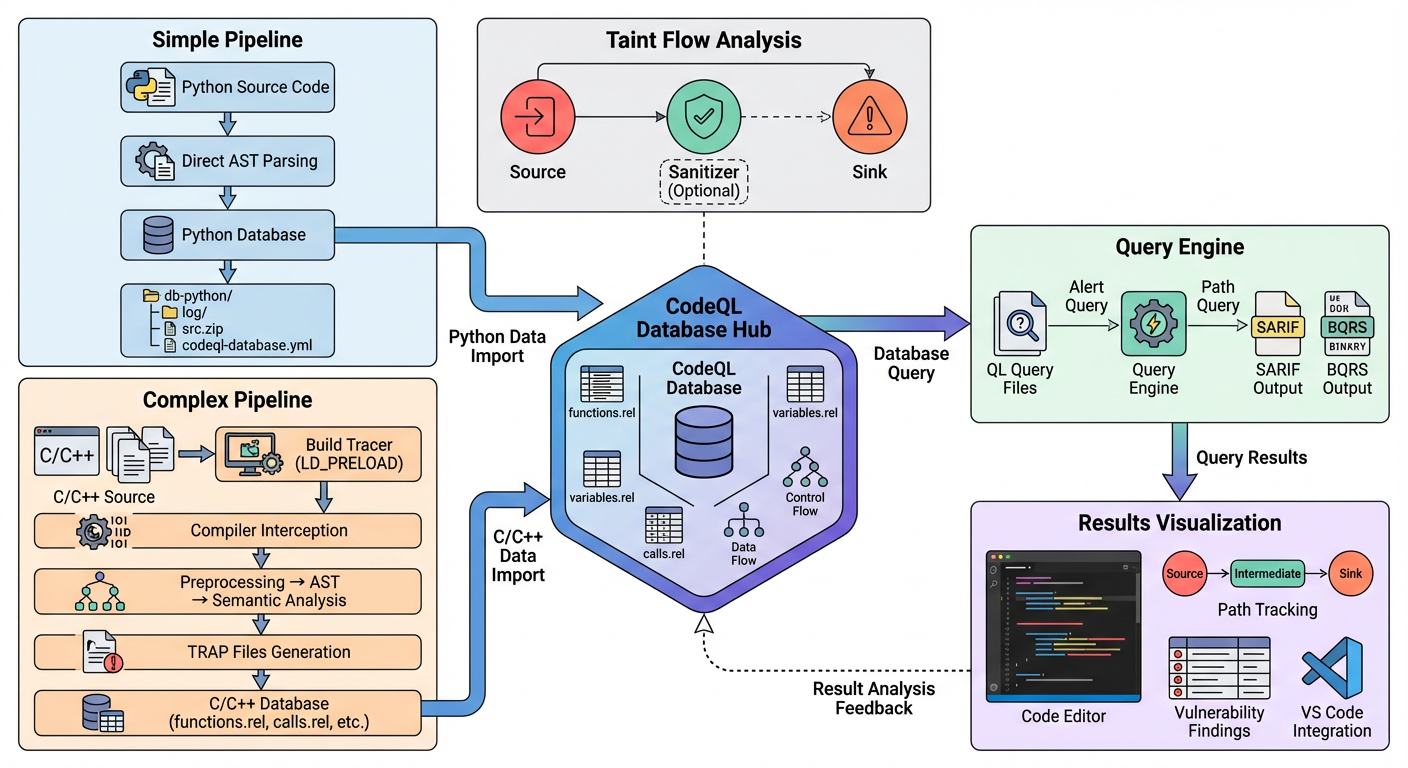
静态污点分析STA
“静态污点分析” (Static Taint Analysis)
Source
顾名思义—-“源头”,外部输入,就是程序中一个数据流的起点,比如 HttpServletRequest.getParameter() ,程序在这里通过获取HTTP的Get参数引入外部数据,这个就是Source点,后面会使用这个数据或者对这个数据做处理,也就是说一条数据流就从这里开始,所以我们要进行污点分析的话,也就是从这里开始
Web环境中HTTP,Cookie等这些操作被视为Source点。
系统环境System.getenv(“PATH”),命令行参数这些
还有比如说安卓中一些协议交互这些…
Sink
危险点,就是说Source点是一个危险数据的流入,那么Sink点就是危险数据爆发触发的地方
可以简单简化地去理解,我这里举出两个比较常见的漏洞类型
SQL注入中
我们都清楚:SQL注入原理就是用户输入被拼接成 SQL 语句的一部分,导致数据库引擎误将数据当成代码执行
在Java代码中,常见的Sink点就是数据库引擎执行SQL查询的点
如下
java.sql.Statement.executeQuery(String sql)
java.sql.Statement.execute(String sql)那么相应的在PHP中就是如下这些代码形式
mysqli_query()
PDO::query()另外一个类型就是
命令注入中
Command Injection 原理众所众知:
我们数据流向操作系统命令执行函数时,比如说下面这些常见的危险函数
Java: Runtime.getRuntime().exec(String command)
Python: os.system(), subprocess.call() (如果 shell=True)
Node.js: child_process.exec()
这些就是污点可能触发的点,我们要视作Sink点
还有一个需要注意的点
同一个函数,可能是不同漏洞的 Sink:
new File(userInput): 如果userInput是文件名,这是 路径遍历 的 Sink。- 如果系统会解析该文件内容比如说进行XML 解析,那它可能是 XXE的 Sink
Sanitizer
这个翻译过来就是:净化器的意思
很好的一个比喻:如果说 Source 是”病毒”,Sink 是”易感器官”,那么 Sanitizer 就是”口罩”或”疫苗”
Sanitizer分为两个机制
第一种清洗数据,本质上是去修改数据
比如说是HTML 实体编码用于防御XSS这类攻击:
将 <script> 转换为 <script>。浏览器会显示它,但不会执行它。
常见函数: htmlspecialchars() (PHP), DOMPurify.sanitize() (JS), StringEscapeUtils.escapeHtml4() (Java).
还有说就是SQL 转义防御 SQL 注入。将单引号 ' 转换为 \' 或 '' 这种操作等
第二种验证,逻辑上避开危险数据
比如说类型检查,如下如果不是数字类型就避开
if (StringUtils.isNumeric(input)) { ... }还有类似白名单,黑名单这些去逻辑上处理数据
allow:
a,b,c
not allow:
d,e,f我们可以回到CodeQL中来看一看这些概念的应用和体现,这里展示CVE-2025-54802的Path Query查询QL语句
/**
* @kind path-problem
* @name CVE-2025-54802 (narrowed): pyLoad CNL addcrypted arbitrary file write
* @description Tainted HTTP input in cnl_blueprint.addcrypted flowing into open(..., ...) filename (arbitrary file write).
* @id python/cve-2025-54802/narrow
* @severity high
* @precision high
* @tags security, taint, path-traversal, file-write
*/
import python
import semmle.python.dataflow.new.DataFlow
import semmle.python.dataflow.new.TaintTracking
import semmle.python.dataflow.new.RemoteFlowSources
/** ---------- Helpers ---------- */
predicate calleeIsGlobalName(DataFlow::CallCfgNode call, string nm) {
call.getFunction().asCfgNode().getNode() instanceof Name and
call.getFunction().asCfgNode().getNode().(Name).getId() = nm
}
/** limit to cnl_blueprint.py */
predicate inCnlBlueprint(DataFlow::Node n) {
n.getLocation().getFile().getBaseName() = "cnl_blueprint.py"
}
/** limit to function addcrypted */
predicate inAddcrypted(DataFlow::Node n) {
n.getEnclosingCallable().getScope().getName() = "addcrypted"
}
/** ---------- Config ---------- */
module CnlWriteConfig implements DataFlow::ConfigSig {
/**
* Sources: 仅追踪该文件/函数内的远程输入(Flask request.*)等
*/
predicate isSource(DataFlow::Node source) {
source instanceof RemoteFlowSource and
inCnlBlueprint(source) and
inAddcrypted(source)
}
/**
* Sinks:
* - 情形 A: open(<tainted path>, ...) 的第 0 个参数(原先的 sink)
* - 情形 B: receiver of .write(...)(例如 fp.write(...)) —— 需要 isAdditionalFlowStep 将 open 的 filename taint 传播到 open 返回值/with-item
*/
predicate isSink(DataFlow::Node sink) {
(
// A: open(...) 的第 0 参数
exists(DataFlow::CallCfgNode call |
calleeIsGlobalName(call, "open") and
sink = call.getArg(0) and
inCnlBlueprint(sink) and
inAddcrypted(sink)
)
)
or
(
// B: 成员调用 .write(...) 的 receiver 作为 sink
// 这里用 CallCfgNode 来匹配成员调用(call.getFunction().asCfgNode().getNode() 为 Attribute)
exists(DataFlow::CallCfgNode call |
call.getFunction() instanceof DataFlow::AttrRead and
// Attribute 节点的属性名为 "write"
call.getFunction().(DataFlow::AttrRead).getAttributeName() = "write" and
// 将 Attribute 的 qualifier(receiver)作为 sink 节点
sink = call.getFunction().(DataFlow::AttrRead).getObject() and
inCnlBlueprint(sink) and inAddcrypted(sink)
)
)
}
/**
* isAdditionalFlowStep:
* 把 open(...) 的 filename 参数传播到 open() 的调用表达式/返回值(call 节点),
* 并处理 with-item 的情形(wi),以便 open 返回值在后续绑定到变量(如 fp)时能继承 taint。
*
* src 和 dst 都是 DataFlow::Node(可以是 CallCfgNode / WithItem /其它表达式节点)
*/
predicate isAdditionalFlowStep(DataFlow::Node src, DataFlow::Node dst) {
(
// 情形 1: 普通 open(...) 调用:把 arg(0) -> call(call 表示调用表达式/返回值)
exists(DataFlow::CallCfgNode call |
calleeIsGlobalName(call, "open") and
src = call.getArg(0) and
dst = call and
inCnlBlueprint(src) and inAddcrypted(src) and
inCnlBlueprint(dst) and inAddcrypted(dst)
)
)
}
/**
* 不设置净化器(为了命中未修补版本)
*/
predicate isSanitizer(DataFlow::Node node) {
none()
}
}
module Flow = TaintTracking::Global<CnlWriteConfig>;
import Flow::PathGraph
from Flow::PathNode src, Flow::PathNode sink
where Flow::flowPath(src, sink)
select sink.getNode(), src, sink,
"Untrusted data in cnl_blueprint.addcrypted flows into file write (open). Potential path traversal → arbitrary file write.",
src, "source", sink, "sink"可以看出来我们定义了这些逻辑操作去进行污点分析
isSource
isSink
isSanitizer
isAdditionalFlowStepAdditionalFlowStep这个是针对于断流点处理的逻辑
创建QL数据库
这里主要探讨一下Python和C数据库的创建,其实更多地的可以参考官方文档
总的命令结构
codeql database create [--language=<lang>[,<lang>...]] [--github-auth-stdin] [--github-url=<url>] [--source-root=<dir>] [--threads=<num>] [--ram=<MB>] [--command=<command>] [--extractor-option=<extractor-option-name=value>] <options>... -- <database>Python
对于Python项目来说
由于Python是解释语言,就是说他不需要编译步骤,我们直接解析源码
所以可以说Python这种数据是比较好建立,对电脑系统什么环境要求不太高
codeql database create python-database \
--language=python \
--source-root=/path/to/source
# 如果有依赖
codeql database create python-database \
--language=python \
--command="pip install -r requirements.txt" \
--source-root=/path/to/source比如说对于
codeql database create python-db --language=python --source-root=source_code/Shakal-NG-1.3.2/Shakal-NG-1.3.2 最后的数据库结构如下
python-database/
├── db-python/ # Python 特定的数据库文件
├── log/ # 提取日志
├── src. zip # 源代码副本
└── codeql-database.yml # 数据库元数据C/CPP
对于C/CPP这种就可以跟Python的项目做一个对比了
C/CPP属于编译型语言,C/C++ 的语法树AST提取比 Python 复杂得多
codeql database create cpp-database \
--language=cpp \
--command="make" \
--source-root=/path/to/source这里借助AI总结一下C/CPP 创建的过程,可以说是相当复杂和详细的
用户命令: codeql database create db --language=cpp --command="make"
│
├─> [1] CodeQL CLI 启动
│ ├─ 创建临时工作目录
│ ├─ 初始化数据库结构
│ └─ 加载 C/C++ extractor
│
├─> [2] 启动 Build Tracer
│ ├─ 注入进程拦截库 (LD_PRELOAD/DYLD_INSERT_LIBRARIES/Detours)
│ ├─ 设置环境变量
│ └─ 启动用户构建命令 ("make")
│
├─> [3] 监控构建过程
│ ├─ 拦截所有进程创建 (fork/exec/CreateProcess)
│ ├─ 识别编译器调用
│ │ ├─ 检查进程名称 (gcc/g++/clang/cl. exe)
│ │ ├─ 解析编译命令行参数
│ │ └─ 提取编译信息
│ ├─ 记录每个编译调用
│ │ ├─ 源文件路径
│ │ ├─ 包含路径 (-I)
│ │ ├─ 宏定义 (-D)
│ │ ├─ 编译选项 (-std, -O, -W)
│ │ └─ 输出文件 (-o)
│ └─ 生成 compile_commands.json
│
├─> [4] 代码提取 (每个源文件)
│ ├─ 预处理
│ │ ├─ 展开宏
│ │ ├─ 处理 #include
│ │ ├─ 处理条件编译 (#ifdef)
│ │ └─ 生成预处理后的代码
│ ├─ 解析 AST
│ │ ├─ 词法分析
│ │ ├─ 语法分析
│ │ └─ 构建语法树
│ ├─ 语义分析
│ │ ├─ 类型检查
│ │ ├─ 符号解析
│ │ ├─ 重载解析
│ │ └─ 模板实例化
│ └─ 生成 TRAP 文件
│ ├─ 函数定义
│ ├─ 变量声明
│ ├─ 类型信息
│ ├─ 函数调用
│ ├─ 控制流
│ └─ 数据流
│
├─> [5] 导入 TRAP 数据
│ ├─ 合并所有 TRAP 文件
│ ├─ 转换为关系数据库
│ │ ├─ functions 表
│ │ ├─ variables 表
│ │ ├─ calls 表
│ │ └─ ... (其他表)
│ └─ 建立索引
│
└─> [6] 完成
├─ 生成数据库元数据 (codeql-database. yml)
├─ 压缩源代码 (src.zip)
└─ 数据库创建完成这里需要了解一下TRAP文件格式
这种文件是CodeQL的中间文件
主要流如下
代码 -> AST -> TRAP 文件 -> 关系数据库 -> CodeQL 查询C/CPP最后的数据库结构
cpp-database/
├── db-cpp/
│ ├── default/
│ │ ├── functions.rel # 函数定义
│ │ ├── classes. rel # 类和结构体
│ │ ├── variables.rel # 变量
│ │ ├── pointers.rel # 指针关系
│ │ ├── calls.rel # 函数调用
│ │ ├── macros.rel # 宏定义
│ │ └── templates.rel # 模板实例化
├── log/
│ ├── build-tracer.log # 构建追踪日志
│ └── database-create.log
├── src.zip
└── codeql-database. yml可以看一下对于frr这个项目,我们最终在Linux系统下创建命令
codeql database create frr-codeql-db \
--language=cpp \
--command="make -j4"这里j4是时使用 4 个线程(任务)进行编译
对于一些比较老的C项目,建议是先构建Docker特定环境,然后执行创建
build-mode模式
可以重点看一下build-mode这个命令参数,官方已经标记了这些模式的试用语言范围

--build-mode=<mode>
将会用于创建数据库的生成模式。
根据要分析的语言选择生成模式:
none:将会创建的数据库,但不会生成源根。 适用于 C#、Java、JavaScript/TypeScript、Python 和 Ruby。
autobuild:将会通过尝试自动生成源根来创建数据库。 适用于 C/C++、C#、Go、Java/Kotlin 和 Swift。
manual:将会通过使用手动指定的生成命令生成源根来创建数据库。 适用于 C/C++、C#、Go、Java/Kotlin 和 Swift。
使用 --command 创建数据库时,不需要额外指定 '--build-mode manual'这个none模式的话,
具体效果就是CodeQL不会尝试去构建我们的代码,特别是”不会生成源根”
Java/C# 在这种模式下可能只分析源码文件而不进行完整编译
对于AutoBuild模式
会尝试自动探测你的项目是如何构建的
比如找 pom.xml, build.gradle, Makefile, go.mod 等
并自动执行构建命令来提取信息
Log文件
Log文件中有很详细的记录过程
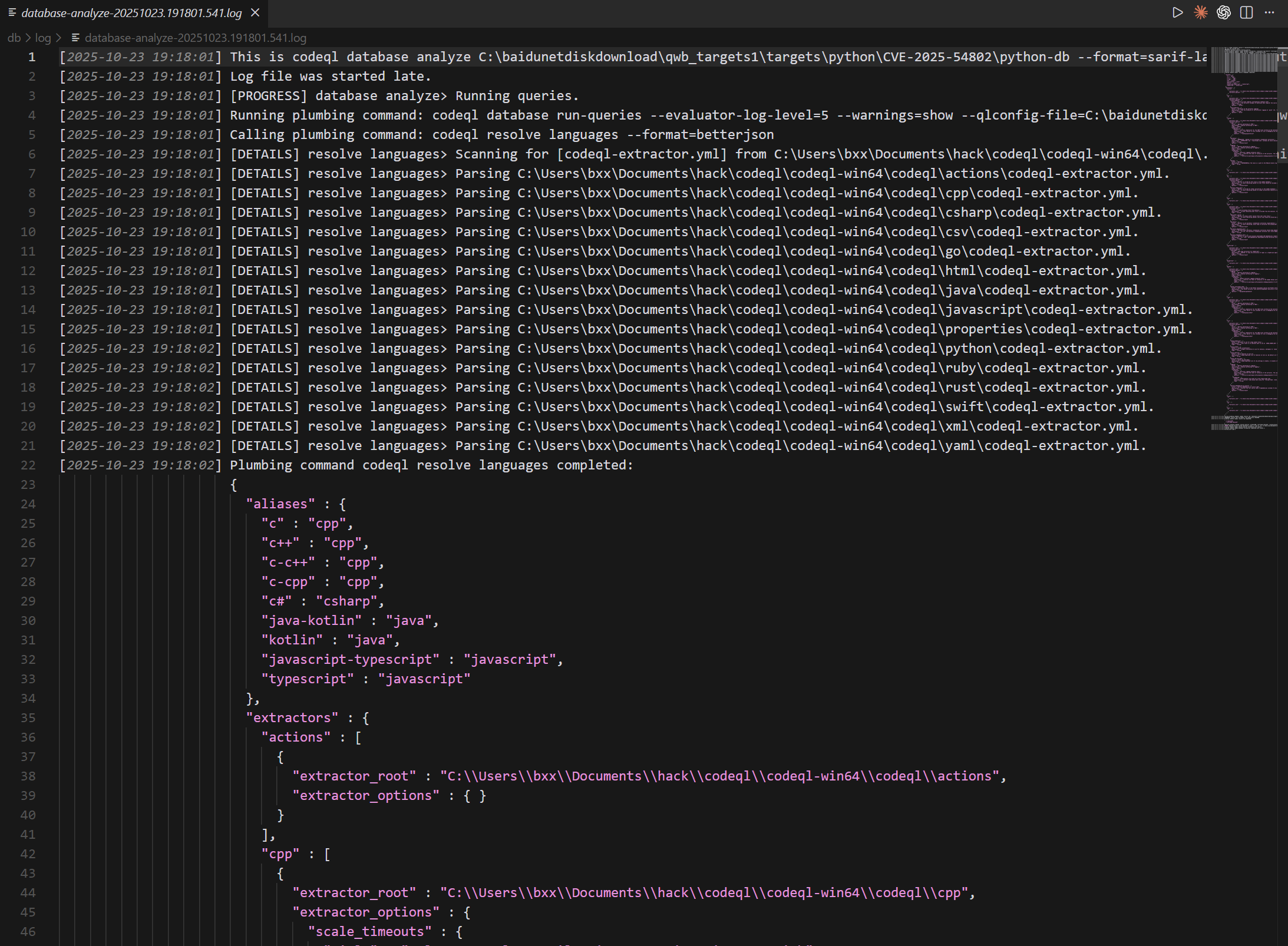
不过一般借助Vscode插件中,就自动解析输出Log文件中错误点了
运行查询QL语句
ql查询主要是分为两种
- Alert 查询:直接指出代码中某个具体位置的问题,比如”这里有空指针风险”。
- Path 查询:分析信息在代码中的流动路径,比如从输入(source)到危险操作(sink)的过程,帮你追踪数据流。
命令行运行
首选必须确保有标准语法库,下载最新or更新查询数据库
codeql pack download codeql/python-queries进行查询
codeql database analyze C:\baidunetdiskdownload\qwb_targets1\targets\python\CVE-2022-22817\source_code\analysis codeql/python-queries --format=sarif-latest --output=results.sarif结果输出成SARIF文件
SARIF 全称是 Static Analysis Results Interchange Format, 中文一般翻译为 静态分析结果交换格式。
它是一种基于 JSON 的标准格式(扩展名
.sarif或.sarif.json), 用于 统一表示静态分析工具的扫描结果
基本格式如下
{
"version": "2.1.0",
"$schema": "https://json.schemastore.org/sarif-2.1.0.json",
"runs": [
{
"tool": {
"driver": {
"name": "CodeQL",
"informationUri": "https://codeql.github.com",
"rules": [
{
"id": "js/incomplete-sanitization",
"shortDescription": { "text": "Incomplete input sanitization" },
"helpUri": "https://codeql.github.com/docs/..."
}
]
}
},
"results": [
{
"ruleId": "js/incomplete-sanitization",
"message": { "text": "Unsanitized user input flows into a SQL query." },
"locations": [
{
"physicalLocation": {
"artifactLocation": { "uri": "src/db/query.js" },
"region": { "startLine": 42 }
}
}
],
"level": "error"
}
]
}
]
}对于SARIF文件,vscode可以使用这个插件去进行预览
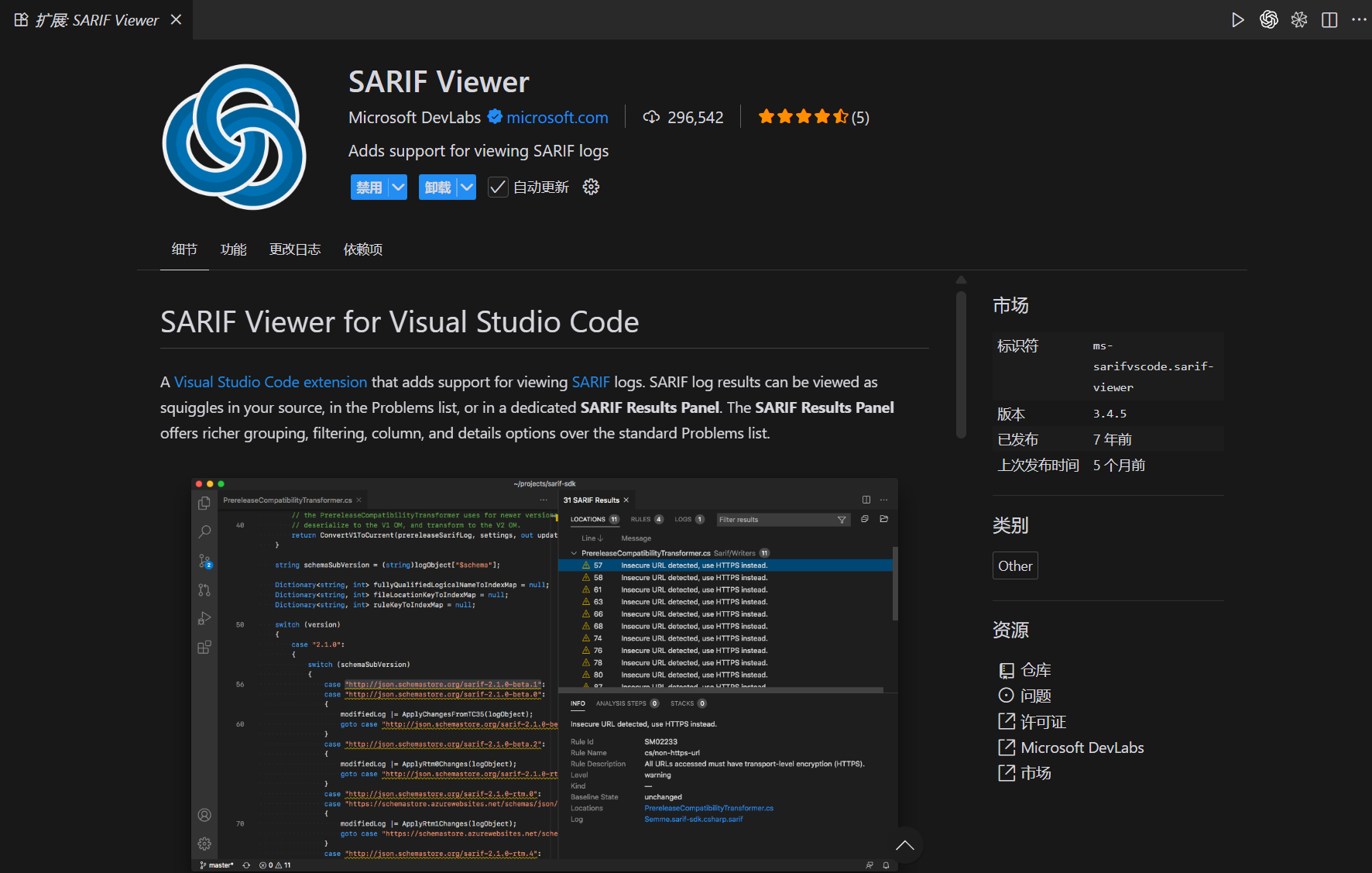
具体效果就是

由于Sarif文件如果在脚本处理的时候,对于路径不太好提取,我们团队做了一个Path提取脚本
https://gist.github.com/bx33661/1640f3e39ab1a81c423a59ecc67b0cf1
提取结果如下
{
"dataFlowPath": [
{
"threadFlows": [
{
"steps": [
{
"stepNumber": 1,
"location": {
"file": "backend/app.py",
"startLine": 587,
"startColumn": 12,
"endColumn": 24,
"description": "ControlFlowNode for Attribute",
"nodeType": "Source"
}
},
{
"stepNumber": 2,
"location": {
"file": "backend/app.py",
"startLine": 587,
"startColumn": 5,
"endColumn": 9,
"description": "ControlFlowNode for data",
"nodeType": "Intermediate"
}
},
{
"stepNumber": 3,
"location": {
"file": "backend/app.py",
"startLine": 593,
"startColumn": 22,
"endColumn": 26,
"description": "ControlFlowNode for data",
"nodeType": "Intermediate"
}
},
{
"stepNumber": 4,
"location": {
"file": "backend/app.py",
"startLine": 593,
"startColumn": 22,
"endColumn": 54,
"description": "ControlFlowNode for Attribute()",
"nodeType": "Intermediate"
}
},
{
"stepNumber": 5,
"location": {
"file": "backend/app.py",
"startLine": 593,
"startColumn": 5,
"endColumn": 19,
"description": "ControlFlowNode for experiment_dir",
"nodeType": "Intermediate"
}
},
{
"stepNumber": 6,
"location": {
"file": "backend/app.py",
"startLine": 632,
"startColumn": 13,
"endColumn": 31,
"description": "ControlFlowNode for abs_experiment_dir",
"nodeType": "Intermediate"
}
},
{
"stepNumber": 7,
"location": {
"file": "backend/app.py",
"startLine": 639,
"startColumn": 13,
"endColumn": 28,
"description": "ControlFlowNode for experiment_file",
"nodeType": "Intermediate"
}
},
{
"stepNumber": 8,
"location": {
"file": "backend/app.py",
"startLine": 640,
"startColumn": 35,
"endColumn": 50,
"description": "ControlFlowNode for experiment_file",
"nodeType": "Sink"
}
}
]
}
]
}
]
}查询结果还可以输出一种bqrs文件,这是 CodeQL 查询结果的二进制存储格式
codeql query run \
--database=my-database \
--output=results.bqrs \
query.ql命令行是支持将bqrs文件解码成json和CSV
# CSV
codeql bqrs decode \
--format=csv \
--output=results.csv \
results.bqrs
# JSON
codeql bqrs decode \
--format=json \
--output=results.json \
results.bqrs
# 查看 BQRS 信息
codeql bqrs info results.bqrs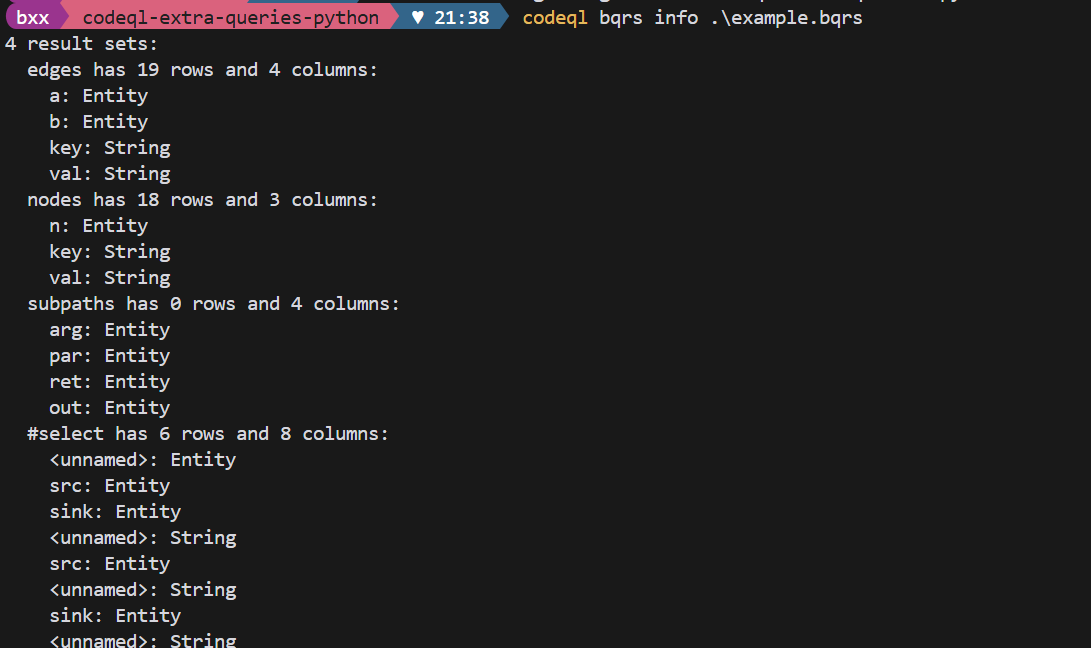
VScode插件生态运行
官方提供插件
这个就是图形化操作,引入DB,运行就行,需要做的就是配好环境统一版本信息
PACK目录
pack 是 CodeQL 的分发单元,用于组织 queries(查询)、libraries(ql 库)、tests(测试)、元数据和对其他 pack 的依赖
不过这些东西主要依赖自动创建,我们可以简单了解一下
主要结构,官方文档示例如下
packs/
my-security-pack/
codeql-pack.yml # pack 声明(必须)
codeql-pack.lock.yml # lock 文件(可选但推荐提交)
queries/
javascript/
sql-injection.ql
crypto-check.ql
ql/ # 可选:自定义 QL 库源码
mylib/
MyHelpers.qll
lib/ # 可选:用来打包的 JS/TS 辅助文件(若有)
tests/
test-suite.qls
docs/
README.md我们重点看一下codeql-pack.yml
---
library: false
warnOnImplicitThis: false
name: getting-started/codeql-extra-queries-python
version: 1.0.0
dependencies:
codeql/python-all: ^4.0.17
再看一下codeql-pack.lock.yml(锁定文件)
记录所有依赖 pack 的精确解析结果(具体版本、commit 或来源)
---
lockVersion: 1.0.0
dependencies:
codeql/concepts:
version: 0.0.7
codeql/controlflow:
version: 2.0.17
codeql/dataflow:
version: 2.0.17
codeql/mad:
version: 1.0.33
codeql/python-all:
version: 4.0.17
codeql/regex:
version: 1.0.33
codeql/ssa:
version: 2.0.9
codeql/threat-models:
version: 1.0.33
codeql/tutorial:
version: 1.0.33
codeql/typetracking:
version: 2.0.17
codeql/util:
version: 2.0.20
codeql/xml:
version: 1.0.33
codeql/yaml:
version: 1.0.33
compiled: false
评论区
使用 GitHub Discussions 驱动,欢迎留言交流。