llm-universe-Task3 搭建知识库

使用智谱embeddingAPI
from zhipuai import ZhipuAI
def zhipu_embedding(text: str):
api_key = api
client = ZhipuAI(api_key=api_key)
response = client.embeddings.create(
model="embedding-2",
input=text,
)
return response
text = '测试样例:大家好,我的名字是BX同学'
response = zhipu_embedding(text=text)
我们在这里定义一个 response的量,他的类型是 zhipuai.types.embeddings.EmbeddingsResponded
print(f'response类型为:{type(response)}')
print(f'embedding类型为:{response.object}')
print(f'生成embedding的model为:{response.model}')
print(f'生成的embedding长度为:{len(response.data[0].embedding)}')
print(f'embedding(前10)为: {response.data[0].embedding[:10]}')
返回结果如下:
response类型为:<class 'zhipuai.types.embeddings.EmbeddingsResponded'>
embedding类型为:list
生成embedding的model为:embedding-2
生成的embedding长度为:1024
embedding(前10)为: [-0.026457634, 0.057955023, -0.008275202, -0.051532384, 0.04349824, -0.00055682287, 0.010337204, -0.0014031194, 0.014186299, 0.039998353]
对文件进行数据处理
根据DW的教程,我们在这里选取两本开源的书:
上传文件
由于我是用的是阿里云服务器学习的,这里采用ftp的方式上传这两本书
使用的软件是Xftp
这里已经上传成功了!
文件数据的读取
读取PDF
LangChain 的 PyMuPDFLoader 来读取知识库的 PDF 文件。
PyMuPDFLoader 是 PDF 解析器中速度最快的一种,结果会包含 PDF 及其页面的详细元数据,并且每页返回一个文档。
from langchain.document_loaders.pdf import PyMuPDFLoader
# 创建一个 PyMuPDFLoader Class 实例,输入为待加载的 pdf 文档路径
loader = PyMuPDFLoader("../data/LLM-v1.0.0.pdf")
# 调用 PyMuPDFLoader Class 的函数 load 对 pdf 文件进行加载
pdf_pages = loader.load()
文档扫描后,储存在 paf_pages这个量中
print(f"载入后的变量类型为:{type(pdf_pages)},", f"该 PDF 一共包含 {len(pdf_pages)} 页")
载入后的变量类型为:<class 'list'>, 该 PDF 一共包含 373 页
- type(pdf_pages) --- 查看pages的一个类型
- len(pdf_pages) --- 查看有多少页数
pdf_page = pdf_pages[1]
#导入第二页的内容
print(f"每一个元素的类型:{type(pdf_page)}.",
f"该文档的描述性数据:{pdf_page.metadata}",
f"查看该文档的内容:\n{pdf_page.page_content}",
sep="\n------\n")
- 元素类型是langchain_core.documents.base.Document
输出内容如下:(输出的是本书第二页的内容)
每一个元素的类型:<class 'langchain_core.documents.base.Document'>.
------
该文档的描述性数据:{'source': '../data/LLM-v1.0.0.pdf', 'file_path': '../data/LLM-v1.0.0.pdf', 'page': 1, 'total_pages': 373, 'format': 'PDF 1.7', 'title': '', 'author': '', 'subject': '', 'keywords': '', 'creator': '', 'producer': 'iLovePDF', 'creationDate': '', 'modDate': 'D:20230817062022Z', 'trapped': ''}
------
查看该文档的内容:
7. 文本扩展 Expanding @邹雨衡
8. 聊天机器人 Chatbot @长琴
9. 总结 @长琴
附1 使用 ChatGLM 进行学习 @宋志学
二、搭建基于 ChatGPT 的问答系统
注:吴恩达《Building Systems with the ChatGPT API》课程中文版
目录:
1. 简介 Introduction @Sarai
2. 模型,范式和 token Language Models, the Chat Format and Tokens @仲泰
3. 检查输入-分类 Classification @诸世纪
4. 检查输入-监督 Moderation @诸世纪
5. 思维链推理 Chain of Thought Reasoning @万礼行
6. 提示链 Chaining Prompts @万礼行
7. 检查输入 Check Outputs @仲泰
8. 评估(端到端系统)Evaluation @邹雨衡
9. 评估(简单问答)Evaluation-part1 @陈志宏、邹雨衡
10. 评估(复杂问答)Evaluation-part2 @邹雨衡
11. 总结 Conclusion @Sarai
三、使用 LangChain 开发应用程序
...
1. 简介 Introduction @Joye
2. 加载文档 Document Loading @Joye
3. 文档切割 Document Splitting @苟晓攀
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
读取md文件
from langchain.document_loaders.markdown import UnstructuredMarkdownLoader
loader = UnstructuredMarkdownLoader("路径")
md_pages = loader.load()
....
数据的处理和清洗:
数据处理是一个很重要的过程,在DW的教程中作为示例只是简单地利用正则表达式清洗了一下
\n符号
利用正则表达式进行处理
import re
pattern = re.compile(r'[^\u4e00-\u9fff](\n)[^\u4e00-\u9fff]', re.DOTALL)
"""
re.compile 用于编译正则表达式模式,以便在后续代码中重复使用。
r'[^\u4e00-\u9fff](\n)[^\u4e00-\u9fff]' 是正则表达式模式。
[^\u4e00-\u9fff] 匹配任何非中文字符。
(\n) 匹配一个换行符,并将其放入捕获组。
[^\u4e00-\u9fff] 再次匹配任何非中文字符。
re.DOTALL 标志表示点 (.) 符号可以匹配任何字符,包括换行符,但在这个模式中没有直接用到它,因为没有使用点符号。
"""
pdf_page.page_content = re.sub(pattern, lambda match: match.group(0).replace('\n', ''), pdf_page.page_content)
"""
re.sub 函数用于将匹配到的模式替换为指定的字符串。
pattern 是之前定义的正则表达式模式。
lambda match: match.group(0).replace('\n', '') 是一个匿名函数,用于指定替换的逻辑。
match 是正则表达式匹配对象。
match.group(0) 返回整个匹配到的字符串。
.replace('\n', '') 将匹配到的字符串中的换行符去掉。
pdf_page.page_content 是被处理的文本。
"""
#这里用到的是lambda表达式
print(pdf_page.page_content)
#输出打印结果
这段代码所能达到的效果是:
- **在文本 **
pdf_page.page_content中,查找所有位于非中文字符之间的换行符。 - 将这些换行符删除。
pdf_page.page_content = pdf_page.page_content.replace('•', '')
pdf_page.page_content = pdf_page.page_content.replace(' ', '')
print(pdf_page.page_content)
7.文本扩展Expanding@邹雨衡
8.聊天机器人Chatbot@长琴
9.总结@长琴
附1使用ChatGLM进行学习@宋志学
二、搭建基于ChatGPT的问答系统
注:吴恩达《BuildingSystemswiththeChatGPTAPI》课程中文版
目录:1.简介Introduction@Sarai2.模型,范式和tokenLanguageModels,theChatFormatandTokens@仲泰
3.检查输入-分类Classification@诸世纪
4.检查输入-监督Moderation@诸世纪
5.思维链推理ChainofThoughtReasoning@万礼行
6.提示链ChainingPrompts@万礼行
7.检查输入CheckOutputs@仲泰
8.评估(端到端系统)Evaluation@邹雨衡
9.评估(简单问答)Evaluation-part1@陈志宏、邹雨衡
10.评估(复杂问答)Evaluation-part2@邹雨衡
11.总结Conclusion@Sarai
三、使用LangChain开发应用程序
注:吴恩达《LangChainforLLMApplicationDevelopment》课程中文版
目录:1.简介Introduction@Sarai2.模型,提示和解析器Models,PromptsandOutputParsers@Joye3.存储Memory@徐虎
4.模型链Chains@徐虎
5.基于文档的问答QuestionandAnswer@苟晓攀
6.评估Evaluation@苟晓攀
7.代理Agent@Joye8.总结Conclusion@Sarai
四、使用LangChain访问个人数据
注:吴恩达《LangChainChatwithYourData》课程中文版
目录:1.简介Introduction@Joye2.加载文档DocumentLoading@Joye3.文档切割DocumentSplitting@苟晓攀
数据分块

- chunk_size 指每个块包含的字符或 Token (如单词、句子等)的数量
- chunk_overlap 指两个块之间共享的字符数量,用于保持上下文的连贯性,避免分割丢失上下文信息
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 知识库中单段文本长度
CHUNK_SIZE = 500
# 知识库中相邻文本重合长度
OVERLAP_SIZE = 50
# 使用递归字符文本分割器
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=CHUNK_SIZE,
chunk_overlap=OVERLAP_SIZE
)
text_splitter.split_text(pdf_page.page_content[0:1000])

完成的实验
实验目的完成完整的向量库的搭建
import os
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
file_paths = []
folder_path = '../data'
for root, dirs, files in os.walk(folder_path):
for file in files:
file_path = os.path.join(root, file)
file_paths.append(file_path)
print(file_paths[:3])
“““
['../data/pumpkin_book.pdf', '../data/LLM-v1.0.0.pdf']
”””
from langchain.document_loaders.pdf import PyMuPDFLoader
from langchain.document_loaders.markdown import UnstructuredMarkdownLoader
# 遍历文件路径并把实例化的loader存放在loaders里
loaders = []
for file_path in file_paths:
file_type = file_path.split('.')[-1]
if file_type == 'pdf':
loaders.append(PyMuPDFLoader(file_path))
elif file_type == 'md':
loaders.append(UnstructuredMarkdownLoader(file_path))
# 下载文件并存储到text
texts = []
for loader in loaders: texts.extend(loader.load())
text = texts[1]
print(f"每一个元素的类型:{type(text)}.",
f"该文档的描述性数据:{text.metadata}",
f"查看该文档的内容:\n{text.page_content[0:]}",
sep="\n------\n")
响应结果如下:
每一个元素的类型:<class 'langchain_core.documents.base.Document'>.
------
该文档的描述性数据:{'source': '../data/pumpkin_book.pdf', 'file_path': '../data/pumpkin_book.pdf', 'page': 1, 'total_pages': 196, 'format': 'PDF 1.5', 'title': '', 'author': '', 'subject': '', 'keywords': '', 'creator': 'LaTeX with hyperref', 'producer': 'xdvipdfmx (20200315)', 'creationDate': "D:20231117152045-00'00'", 'modDate': '', 'trapped': ''}
------
查看该文档的内容:
前言
“周志华老师的《机器学习》
(西瓜书)是机器学习领域的经典入门教材之一,周老师为了使尽可能多的读
者通过西瓜书对机器学习有所了解, 所以在书中对部分公式的推导细节没有详述,但是这对那些想深究公式推
导细节的读者来说可能“不太友好”
,本书旨在对西瓜书里比较难理解的公式加以解析,以及对部分公式补充
具体的推导细节。
”
读到这里,大家可能会疑问为啥前面这段话加了引号,因为这只是我们最初的遐想,后来我们了解到,周
老师之所以省去这些推导细节的真实原因是,他本尊认为“理工科数学基础扎实点的大二下学生应该对西瓜书
中的推导细节无困难吧,要点在书里都有了,略去的细节应能脑补或做练习”
。所以...... 本南瓜书只能算是我
等数学渣渣在自学的时候记下来的笔记,希望能够帮助大家都成为一名合格的“理工科数学基础扎实点的大二
下学生”
。
使用说明
• 南瓜书的所有内容都是以西瓜书的内容为前置知识进行表述的,所以南瓜书的最佳使用方法是以西瓜书
为主线,遇到自己推导不出来或者看不懂的公式时再来查阅南瓜书;
• 对于初学机器学习的小白,西瓜书第1 章和第2 章的公式强烈不建议深究,简单过一下即可,等你学得
有点飘的时候再回来啃都来得及;
...
,即可加入“南瓜书读者交流群”
版权声明
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 切分文档
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, chunk_overlap=50)
split_docs = text_splitter.split_documents(texts)
from zhipuai_embedding import ZhipuAIEmbeddings
# 定义 Embeddings
# embedding = OpenAIEmbeddings()
embedding = ZhipuAIEmbeddings()
# embedding = QianfanEmbeddingsEndpoint()
# 定义持久化路径
persist_directory = '../chroma'
创建一个Chroma的库
from langchain.vectorstores.chroma import Chroma
vectordb = Chroma.from_documents(
documents=split_docs[:20], # 为了速度,只选择前 20 个切分的 doc 进行生成;使用千帆时因QPS限制,建议选择前 5 个doc
embedding=embedding,
persist_directory=persist_directory # 允许我们将persist_directory目录保存到磁盘上
)
vectordb.persist()
/root/miniconda3/envs/llm-universe/lib/python3.10/site-packages/langchain_core/_api/deprecation.py:139: LangChainDeprecationWarning: Since Chroma 0.4.x the manual persistence method is no longer supported as docs are automatically persisted.
warn_deprecated(
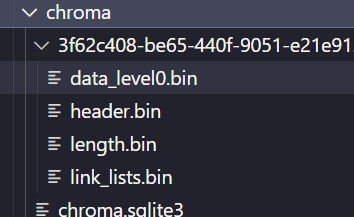
如下图所示数据已存储在 chroma下
相似度检索
概念的简单理解:
相似度搜索的核心是度量两个嵌入向量之间的相似度。常用的相似度度量方法包括:
- 余弦相似度(Cosine Similarity): 衡量两个向量的夹角余弦值,范围在-1到1之间,1表示完全相同,0表示正交,-1表示完全相反。
- 欧氏距离(Euclidean Distance): 衡量两个向量在空间中的直线距离,距离越小表示越相似。
- 内积(Dot Product): 用于衡量向量之间的相似性,内积值越大表示越相似。
MMR检索
MMR(最大边缘相关模型,Maximal Marginal Relevance)是一种在信息检索和自然语言处理领域中广泛应用的算法。它的主要目标是在文档排序和摘要生成等任务中平衡相关性和新颖性,为用户提供既相关又包含新信息的结果。
MMR算法的基本思想是同时考量查询与文档的相关度,以及文档之间的相似度。相关度确保返回结果对查询高度相关,而相似度则鼓励不同语义的文档被包含进结果集。具体来说,它计算每个候选文档与查询的相关度,并减去与已经选入结果集的文档的相似度。这样更不相似的文档会有更高的得分,从而实现了多样性的检索。
在实际应用中,比如使用LangChain构建知识库问答系统时,MMR算法可以帮助解决重复文档问题。例如,当知识库中存在内容相似或重复的文档时,MMR算法能够通过考虑文档之间的相似性,为用户提供既相关又多样的检索结果。
MMR算法的数学公式中,R是输入的列表,Di是集合R的成员,S是当前返回的结果集。Sim1(Di,Q)表示候选文档Di与查询Q的相关度,Sim2(Di,Dj)表示候选文档Di与已选结果集S中文档Dj的相似度。通过迭代计算,选择具有最大MMR值的文档加入到结果集S中。
总之,MMR是一种简单高效的算法,能够平衡相关性和多样性,适用于需要多样信息的应用场景。它在信息检索、自然语言处理等领域发挥着重要作用,帮助用户从大量信息中找到真正需要的信息




{kind=link}